Mastering Database Isolation A Guide for Modern Developers
Discover how database isolation levels protect your data from dirty reads, non-repeatable reads, and phantom reads. A complete guide for developers building scalable, concurrent systems.
Have you ever wondered how massive ecommerce platforms process millions of orders without crossing wires or messing up your shopping cart? The secret sauce is Database Isolation.
In my two decades of optimizing content and architecting web solutions, I have seen how crucial it is to understand these backend fundamentals — especially when you are diving deep into scalable system design where concurrent usage can bring an application to its knees if not properly managed.
Today we will break down how isolation works, the read phenomena that threaten your data, and the isolation levels that keep everything running smoothly.
.png)
How Database Isolation is Achieved
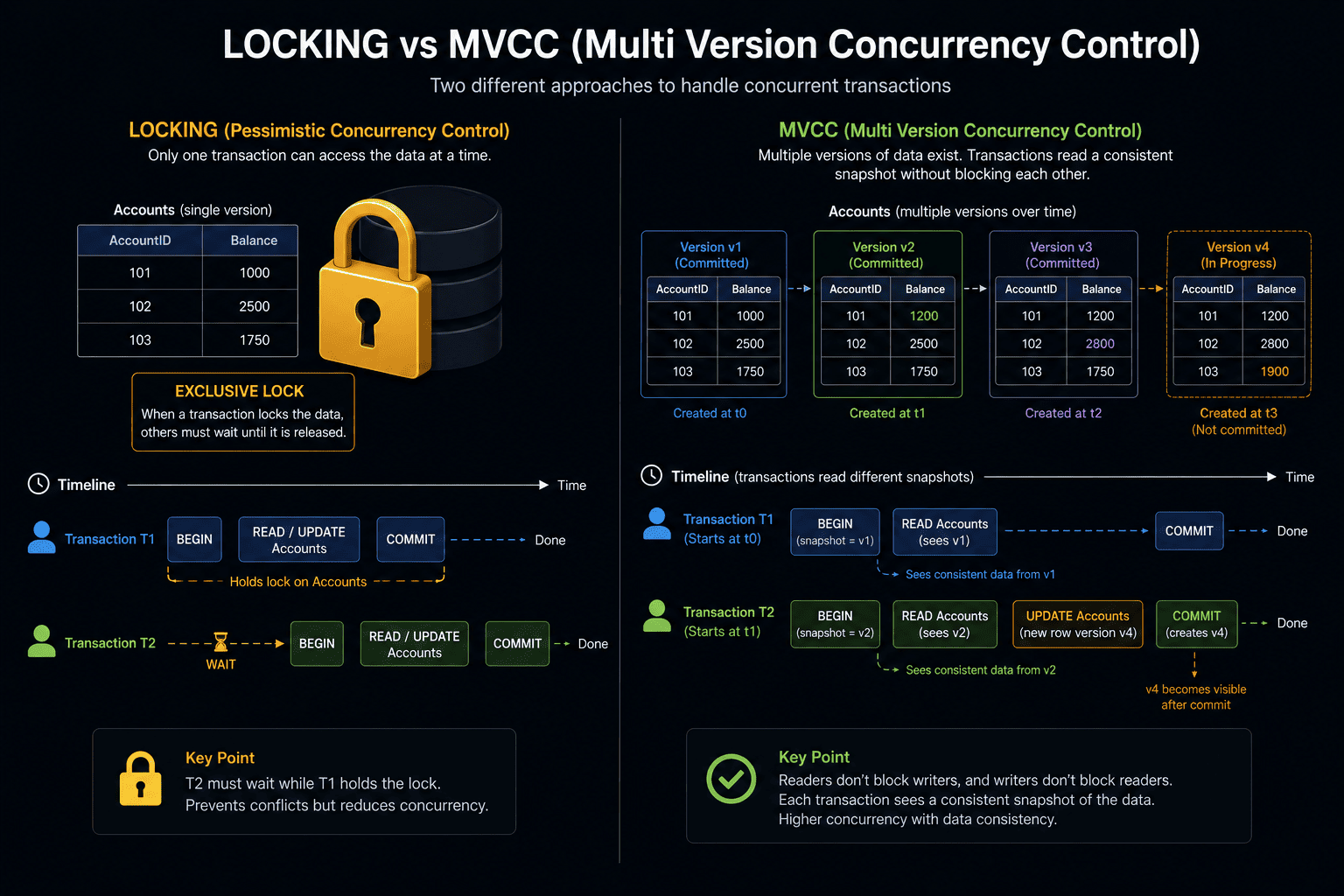
Isolation ensures that concurrent transactions in a database act completely independent of one another. To pull this off, database systems generally use two main strategies: Locking and Multi-Version Concurrency Control (MVCC).
Lockingacts as a strict gatekeeper — it blocks other transactions from reading or writing data until the current transaction is completeMVCCcreates parallel realities for your data — each transaction works on its own snapshot, so readers never block writers and writers never block readers
The Dreaded Read Phenomena
When multiple transactions happen at the same time without strict rules, things get weird. We call these anomalies read phenomena. Let us look at the three biggest troublemakers.
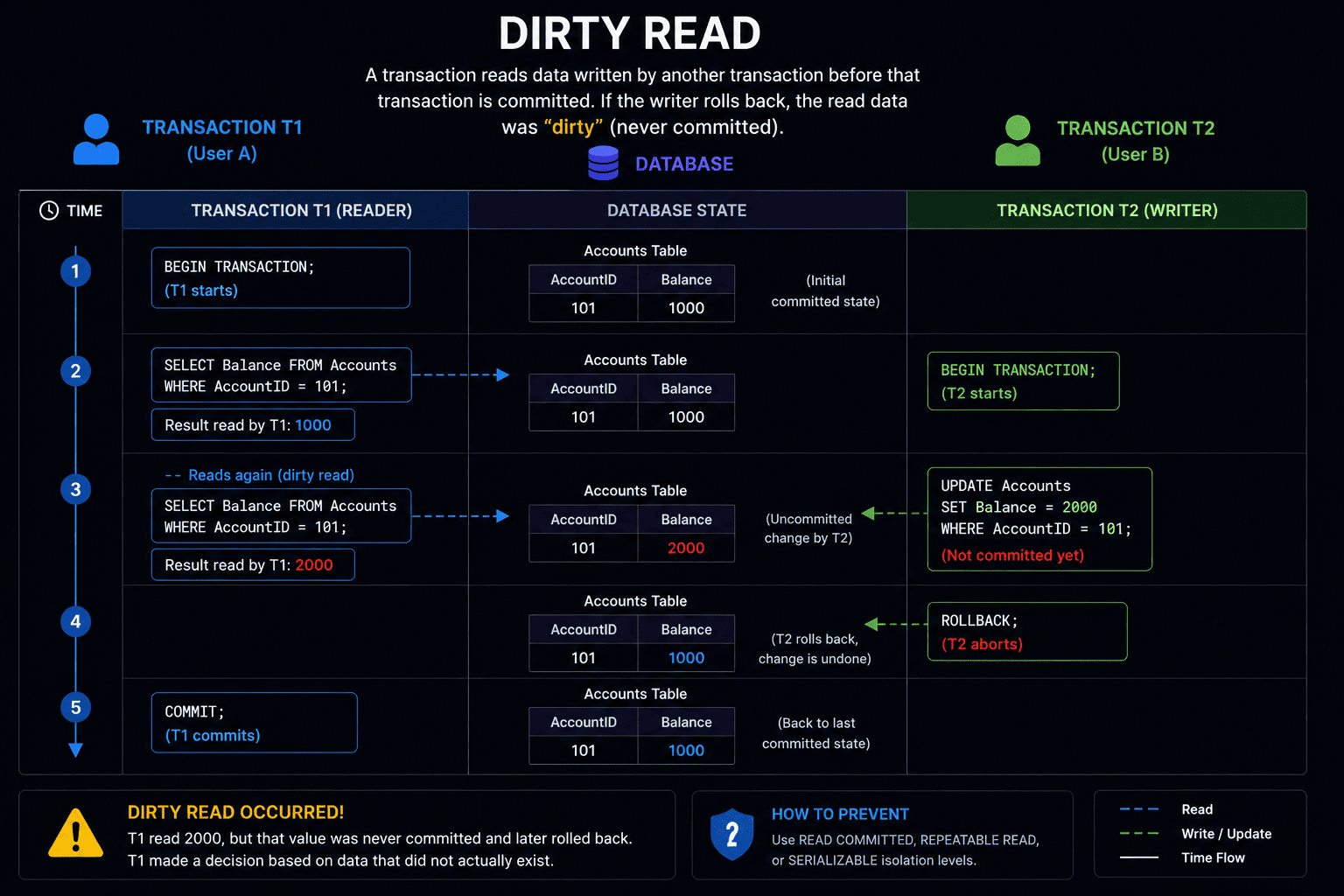
Dirty Read
Imagine you check your bank account and see an extra $100. A background process was depositing that money but suddenly hit an error and rolled back the transaction. Because your read happened exactly before the rollback, you saw data that never technically existed. That is a dirty read.
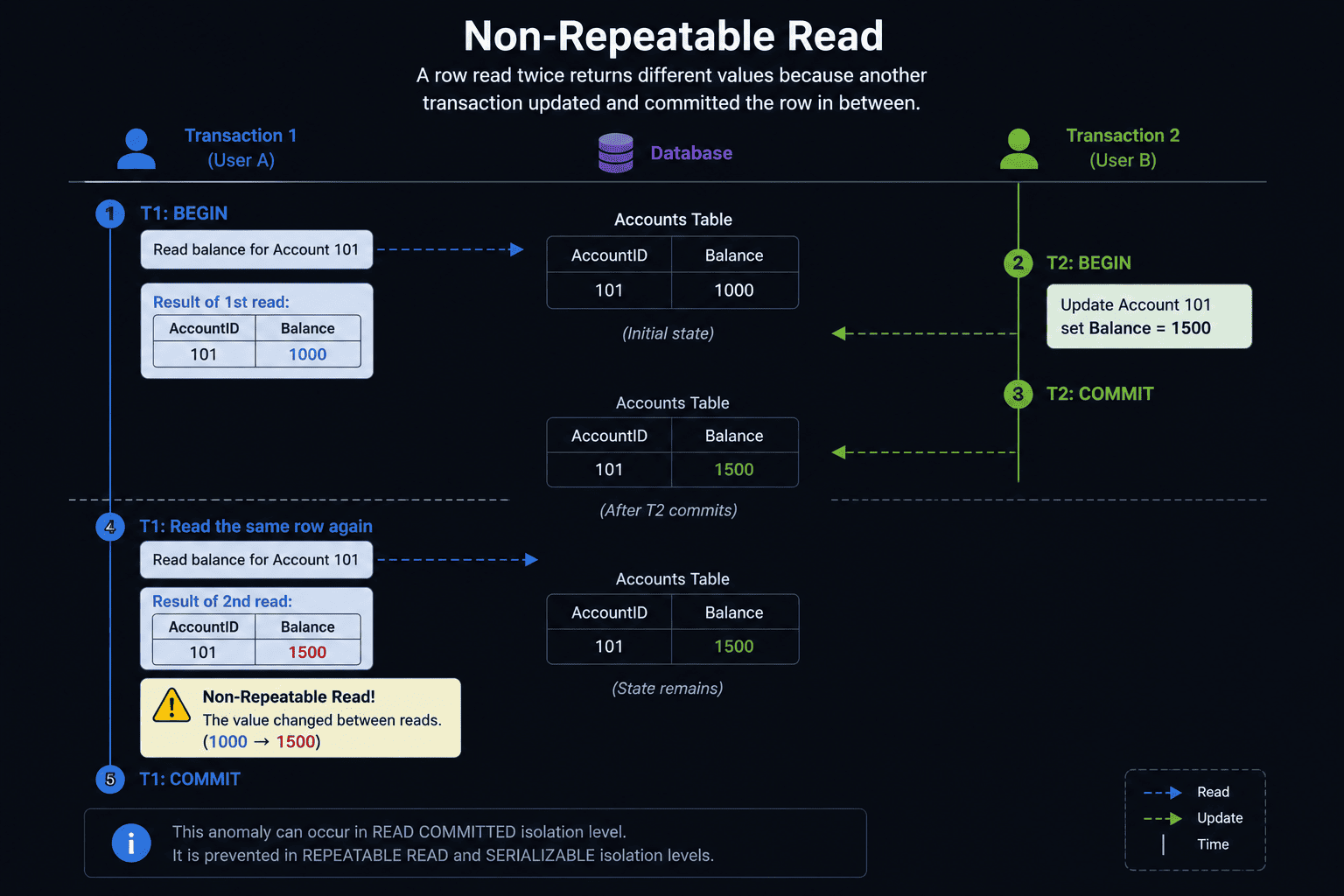
Non-Repeatable Read
You read a product inventory row and see 50 items left. Before you finish your checkout, another user buys 10 items and their transaction commits. If you check that exact same row again within your current transaction, the system now says 40 items are left.
The data changed right under your nose — making your initial read non-repeatable.
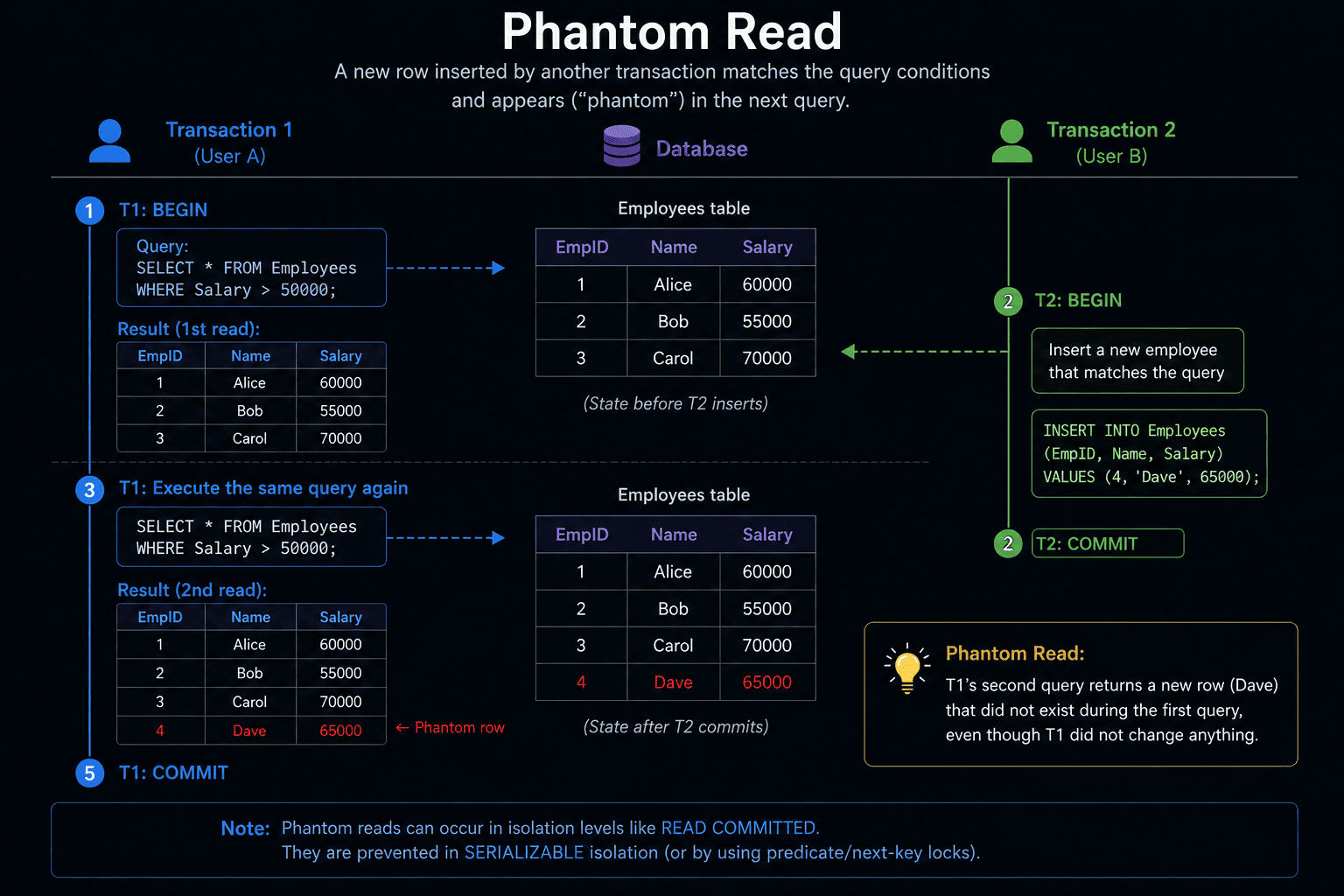
Phantom Read
This one is incredibly sneaky. You run a search for all employees in the IT department and get 10 results. While you are doing this, the HR system adds a brand new employee to the IT department and commits the save. When you run your exact same search again, you suddenly have 11 results.
A phantom record just materialized out of thin air.
Database Isolation Levels
To eliminate these phenomena, databases offer different isolation levels. Think of these as a volume knob — balancing raw speed and perfect data safety.
Read Uncommitted
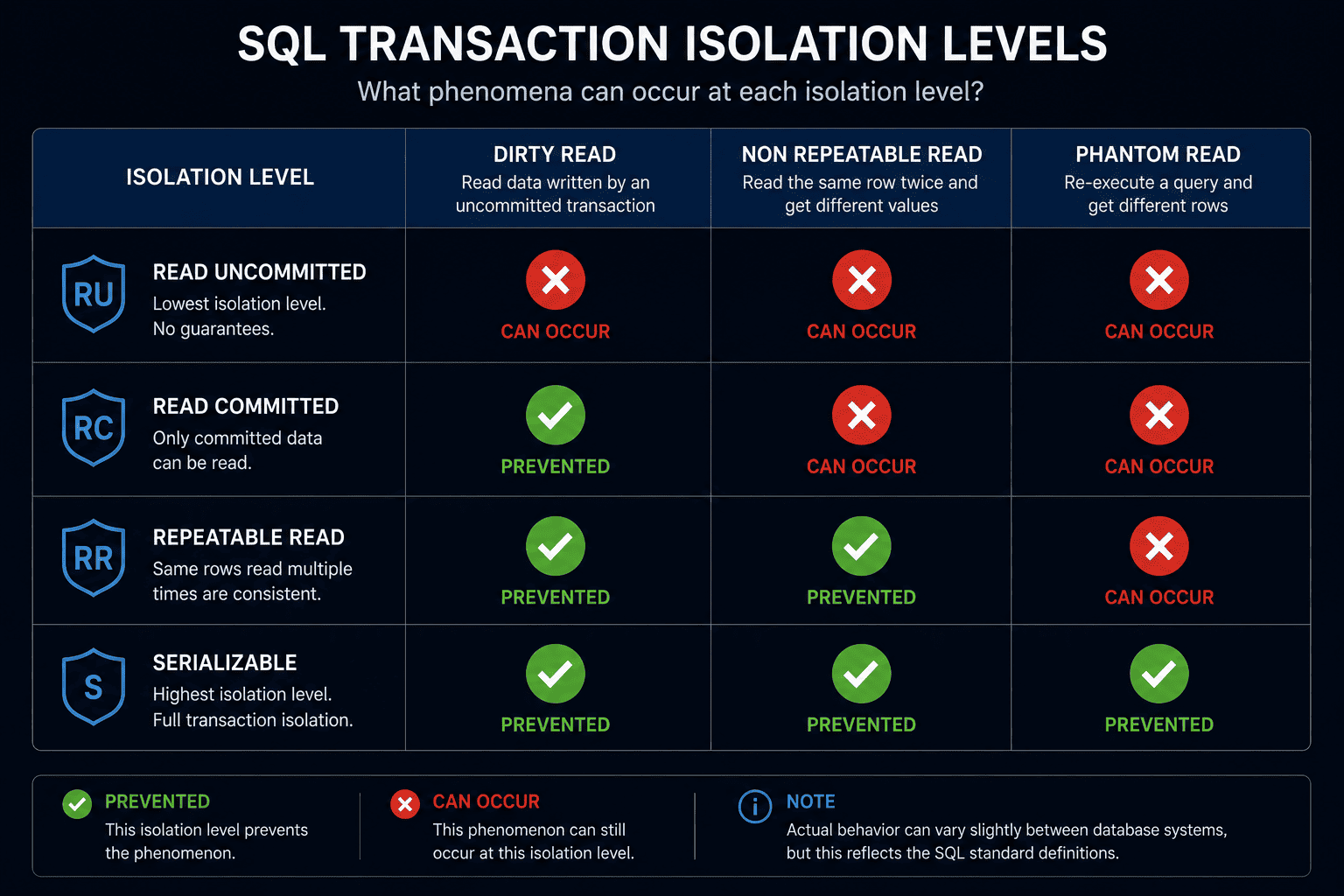
This is the lowest level where almost anything goes. It offers blistering speed but absolutely zero protection. Under this setting you will experience dirty reads, non-repeatable reads, and phantom reads. It is rarely used in systems requiring high accuracy.
Read Committed
Stepping up a level, Read Committed entirely eliminates the dirty read phenomenon because your transaction will only ever see data that has been successfully saved. However, you might still run into non-repeatable reads and phantom reads.
Repeatable Read
This level puts a firm lock on the specific rows you are reading. It solves both dirty reads and non-repeatable reads. Once you read a piece of data, it stays exactly the same until your transaction is completely finished. Phantoms can occasionally still haunt your queries though.
Serializable
This is the ultimate vault. Transactions execute as if they are running sequentially — one right after the other. It wipes out dirty reads, non-repeatable reads, and phantom reads completely. The trade-off is that it can severely slow down your application under heavy load due to all the waiting.
Quick Reference: Isolation Level Matrix
Bookmark this matrix to instantly know which level to pick for your specific application performance and consistency needs.
Understanding database isolation is not just an academic exercise — it is the difference between a system that scales gracefully under millions of concurrent users and one that silently corrupts your data at the worst possible moment. Choose your isolation level deliberately, and your database will reward you with both speed and correctness.