The Single Source of Truth: Mastering Atomicity from Simple Transactions to Distributed Systems
Atomicity is the 'all or nothing' guarantee at the heart of every reliable database. From WAL and undo logs to 2PC and Saga patterns, learn how atomicity scales from a single server to distributed microservices.
Envision you are standing at a vending machine. You insert your cash, select your preferred item, and ... nothing happens. The coil partially extends, your selected product remains lodged, and your cash disappears. As a disheartening experience in everyday life, this kind of disaster in the database world may result in loss of funds, corruption of a user's state, or complete collapse of the system.
To keep these digital calamities from happening, we depend on a basic tenet: Database Atomicity.
It is the "A" in the well-known ACID properties (Atomicity, Consistency, Isolation, Durability), and it exemplifies a very simple, unyielding agreement: A set of database operations will either all successfully execute, or none will. There is no middle ground. There is no "partially done".
Suppose you want to move $100 from your checking account to your savings account. This requires two discrete processes:
- Subtract $100 from checking.
- Add $100 to savings.
If the database crashes immediately after the first step, and we don't have atomicity, you have just lost $100. Atomicity assures that if the second step fails, the first step will be completely reversed, returning the system to its original state. It is the definitive "all or nothing" assurance.
Regardless of whether you're developing a simple personal project or creating microservices for millions of consumers, learning to master atomicity is essential. Let's walk through how this works beginning with the fundamentals and ending with sophisticated distributed systems.
The Fundamentals: Anatomy of a Transaction
At the heart of atomicity lies the concept of a transaction. Consider a transaction to be an abstract grouping of one or more database operations. By placing operations inside of a transaction, we inform the database to treat them collectively as a single, indivisible entity.
BEGIN, COMMIT & ROLLBACK
In order to handle this, relational databases offer three key commands:
- BEGIN — This indicates the beginning of our transaction. We're informing the database "Notice anything I do from here on in belongs collectively".
- COMMIT — After each operation runs without errors, we issue a commit. This irrevocably saves all changes to the database. The transaction was successful.
- ROLLBACK — If there is an error — perhaps a constraint violation, a temporary network disruption, or some type of application level exception — we issue a rollback. This acts like an "undo" button and reverses the state of the database back to exactly what it was prior to issuing the BEGIN command.
Let's take a look at a simple example:
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE id = 1; -- Checking
UPDATE accounts SET balance = balance + 100 WHERE id = 2; -- Savings
COMMIT;If the second UPDATE statement fails and the application detects the error and rolls back, it guarantees that Account 1 won't lose money unjustly.
Dealing with Unforeseen Circumstances: Mid-Transaction Crashes
However, what would happen if the server literally caught fire or crashed in-between those two UPDATE statements? Your application wouldn't have time to roll back.
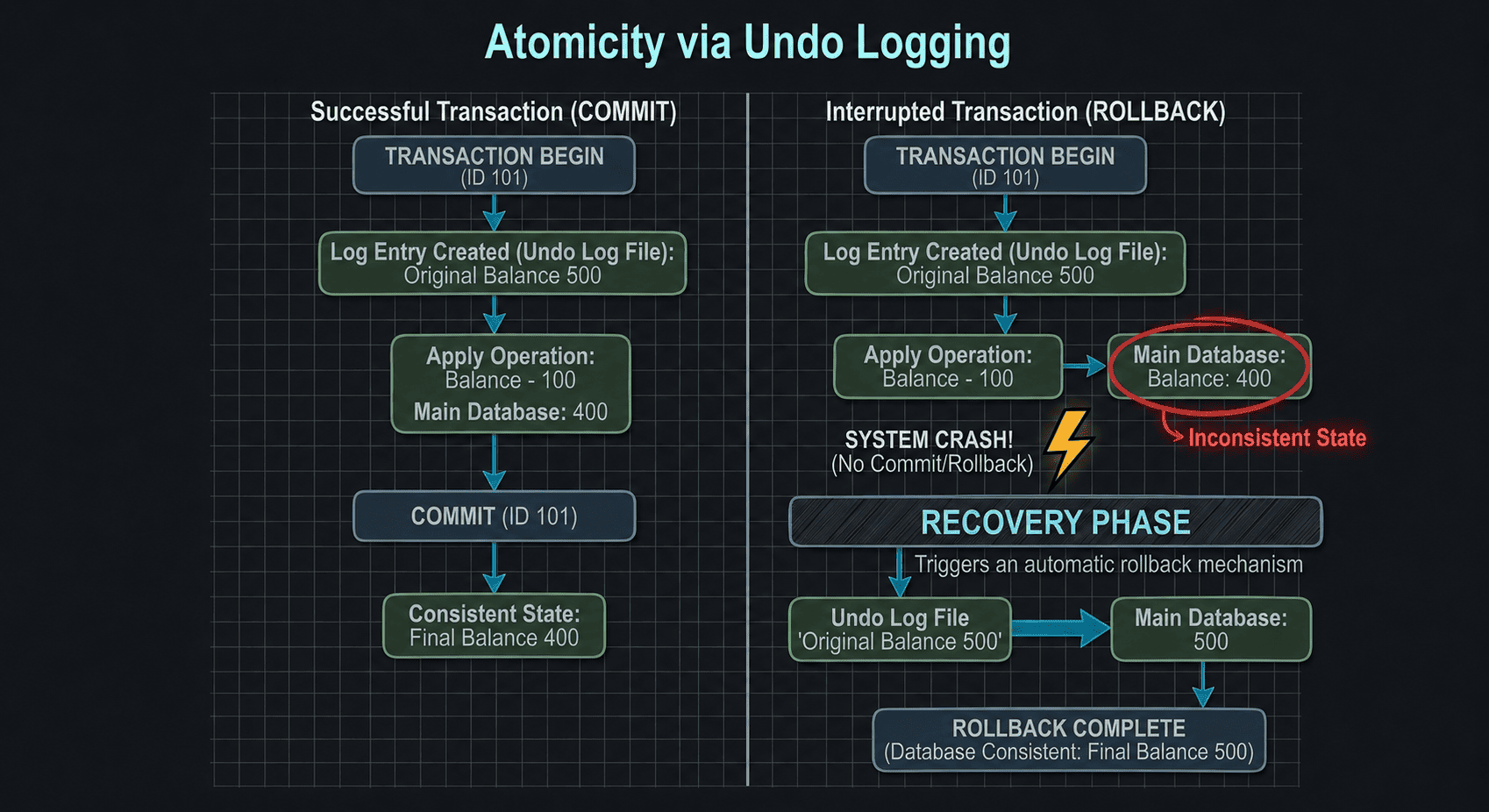
That's where the database engine itself takes over. Upon restarting when the database comes back online, it enters into a recovery process. During this process, it inspects its internal logs to locate any transactions that were begun but didn't receive a COMMIT signal. Since the transaction was terminated prematurely, the database automatically reverses the partial changes made to enforce atomicity even in light of total hardware failure.
Behind-the-Scenes: Implementing Atomicity
Therefore, how does a database memorize and maintain its past state in order to reverse changes made to the database following a crash? It depends on nothing magical; rather it depends on precise record keeping.
Write-Ahead Logging (WAL)
The secret ingredient behind both atomicity and durability is Write-Ahead Logging (WAL). Prior to modifying any of the data files stored directly onto the hard drive itself, a database creates an accurate listing of the pending modifications to an audit trail — referred to as a WAL.
Importantly, this log entry is written to disk prior to considering success status for the transaction.
During recovery, this log serves as the single source of truth for determining which changes occurred.
Undo & Redo Logs
For managing these transitional states, databases utilize several structures within their auditing mechanisms:
| Log Type | Purpose | Example |
|---|---|---|
| Undo Log | Stores previous values for rollback | Balance was $500 before update |
| Redo Log | Stores new values to reapply after crash | Balance should be $400 after commit |
- Undo Logs — These contain the historical values of data. If we alter a value from $500 to $400, the undo log contains $500. In case we wish to initiate a
ROLLBACK(or if the database is recovering from an interrupted transaction), it utilizes the undo log in reversing data back to its previous values. - Redo Logs — These contain current values. Once a transaction completes successfully and before any physical modifications are made to any of the primary data files, the database will utilize the redo log during initialization to reapply previously committed changes that were missed when initiating a restart.
Role of the Transaction Manager
Managing all this is an important component of the database engine known as the Transaction Manager.
The Transaction Manager is essentially the conductor. It:
- Tracks each ongoing transaction (active, completed, failed) and assigns each a unique Transaction ID
- Manages communication with the logging mechanism to assure correct WAL entries are created
- Determines whether any transactional changes are visible to other users (closely related to isolation, controlling visibility based on transaction progression)
When a transaction aborts, it is up to the Transaction Manager to determine which undo logs should be applied.
Scaling Up: Atomicity in Distributed Systems
Everything we've thus far covered assumes there exists a single monolithic database. With atomicity fully controlled by the Transaction Manager and WAL present within that single database server, things are straightforward.
However, today's applications rarely resemble that model. Microservices abound. Data splits across many databases.
Assume again our bank transfer example. However, instead of being executed solely on one server — where the checking account resides in a PostgreSQL database run by an Accounts Service and the savings account resides in a completely independent MySQL database run by a Wealth Service — now each step spans an entirely different system.
How can we establish "all or nothing" behavior when operations occur across two totally unrelated systems? A straightforward BEGIN followed by COMMIT will not suffice since neither database has knowledge about what the other is attempting to accomplish.
Two-Phase Commit (2PC) Protocol
The classic answer to this question is the Two-Phase Commit (2PC) protocol. This introduces an additional component called a Coordinator that manages transactions across multiple Participants (our databases).
It operates in two stages:
Phase 1 — Prepare (Voting): The Coordinator asks all Participants "Can you commit this transaction?" Each Participant must verify its constraints, write its own WAL entries, lock its required rows, and reply Yes or No.
Phase 2 — Commit (Execution):
- If all Participants replied Yes → Coordinator orders all Participants to Commit
- If even one Participant replied No (or timed out) → Coordinator orders all Participants to Abort
Although 2PC offers guaranteed atomicity, it suffers from notorious slowness and fragility. Locks remain held by multiple systems until network answers arrive, which can lead to severe performance bottlenecks. Furthermore, if the Coordinator crashes midway through execution, Participants will be left indefinitely holding locks.
Beyond 2PC: Saga Patterns
Due to performance problems associated with 2PC, most microservice architectures today favor eventual consistency using Saga patterns for handling longer-running transactions.
Saga patterns break down distributed transactions into sequences of smaller localized transactions. Each localized transaction modifies an individual database and publishes an event triggering the next step in the sequence.
Once step 1 completes successfully, step 2 begins execution. What happens if step 3 fails? Given that steps 1 and 2 have already been committed into their respective databases, we cannot simply issue an ordinary ROLLBACK.
Instead, the Saga pattern employs Compensating Transactions. If step 3 fails, the system initiates a pre-defined corrective action undoing the effects of step 2, then initiates yet another corrective action undoing step 1.
If Step 1 was "Charging Credit Card", the Compensating Transaction is "Issuing Refund". It doesn't restore the original database condition — it initiates an additional corrective action.
TCC & Idempotence
An additional common pattern employed in distributed systems is TCC (Try-Confirm/Cancel). Similar to 2PC but implemented at the application layer — a service attempts to reserve required resources. If all services confirm, they are committed. If any fail, reservations are canceled.
Additionally, compensatory actions and API retries require Idempotence when constructing distributed systems. An operation is idempotent if performing it one time produces identical results regardless of whether it is performed once or repeatedly. A payment processing service that is idempotent can identify repeated confirmation requests due to dropped network packets and avoid charging the consumer twice for the same purchase.